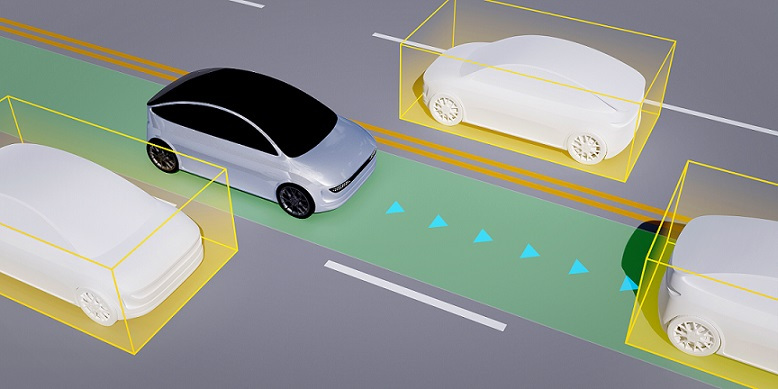
“It‘s similar to when we read kids a picture book. We usually point out specific things and add explanations to help children understand,” Yang told The Korea Herald.
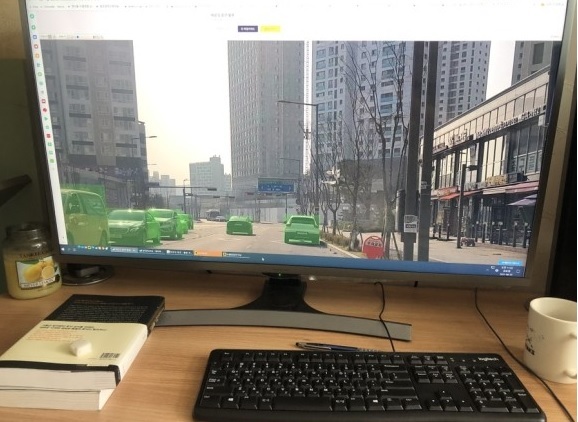
For example, on a picture of a road, she marks every car she sees and adds a tag to denote that they are vehicles. For each image, she gets paid up to 1,000 won ($0.76).
As simple as it sounds, the job is tedious and repetitive. While it does not require any special training, data labelers need to be attentive and able to sit in front of a screen for long periods.
“Data labeling is a part-time job without special requirements, a perfect match for homemakers like me. I can work from my house with my smartphone or laptop. Also, the online platform for the labeling process isn’t that difficult to use,” said Yang, who previously worked as a hotelier until becoming a homemaker 10 years ago.
Data labeling is critical for the development of any AI project. The process is applied not only to images but also to video and audio, according to AI data company AIMMO, AI data company.
Data labeling is what powers now-ubiquitous AI-based voice assistant services like Samsung Electronics‘ Bixby and Apple’s Siri and allows them to understand a variety of intonations and accents. To train voice-activated AI technology, data labelers add verbal explanations to every sentence spoken, AIMMO explains on its website.
‘Nogada’ of the AI era As of 2021, there were 1,481 data labelers across the nation, according to data from Statistics Korea, and 1.07 million people who said they were interested in working in the field, up from 650,000 in 2020.
According to a 2019 report by AI crowdsourcing platform CrowdWorks, more than half of data labelers in the country had taken the job as a way to make a supplementary income. More than 80 percent were salaried workers.
This is why data labelers are called the “nogada” of the digital era. Nogada, meaning manual laborers, usually refers to casual labor at construction sites but can also be used for homemakers earning extra cash by attaching plastic eyes to stuffed dolls or folding pizza boxes.
According to Altovision, a company specializing in creating training datasets for AI, data labelers, who mostly work as freelancers or contract workers, earn a median hourly wage of 17,000 won, in a country where the current minimum wage is 9,160 won.
Demand for data labeling work will increase as the application of AI in business and everyday life continues to grow, said Oh Joo-yang, a director at Altovision.
“Despite increased workplace automation, some jobs are still better performed by humans. It is humans who can teach machines how to think and behave. Data processed and labeled by humans is the lifeblood of AI,” said Oh.
Korea‘s Science and ICT Ministry has created the “Data Dam,” an initiative that is fueling the growth of related industries.
Launched in 2020 as part of the country’s Digital New Deal, the project made data collected from public and private networks available to train AI models across eight key business areas, including self-driving vehicles and healthcare.
To help utilize the data for AI development, the National Information Society under the ministry has launched a financial support program for local tech startups to collect and label data.
The government assistance for each participating company ranges from 1.3 billion won to 5.2 billion won, depending on the size and type of the data. The refined datasets for AI are provided on the government agency‘s open data portal AI Hub.
The Data Dam initiative also provides government funding to small- and medium-sized enterprises and venture startups developing AI-based products, such as virtual fitting programs.
Altovision’s Oh said data labeling is typical of a new form of employment that mobilizes a large pool of online workers for a certain project.
Dubbed “crowd employment,” workers are asked to handle simple tasks that can be done independently through online platforms. The combined efforts of people scattered all over the world result in a specific output, like a wide pool of training datasets for AI.
Currently, most crowd workers are part-timers who want side jobs to earn extra money. But this could change in the future, according to Oh.
“I‘ve seen a crowd worker whose main job is a data labeler. He has worked at different tech startups for more than three years. Crowd work could become a main occupation in the near future, especially among digital-savvy, young people,” he said.
By Choi Jae-hee (
cjh@heraldcorp.com)






![[New faces of Assembly] Architect behind ‘audacious initiative’ believes in denuclearized North Korea](http://res.heraldm.com/phpwas/restmb_idxmake.php?idx=644&simg=/content/image/2024/05/01/20240501050627_0.jpg)








